Traditional games are built with engines such as Unity or Unreal, which rely heavily on manually crafted logic, assets, and rules. Recently, diffusion models have shown strong robustness in long-sequence generation, and researchers have begun applying them to generate interactive game videos. However, current approaches still face challenges of low frame fidelity, inconsistent rendering that fails to match player actions, and frame to frame smooth rendering so that the gameplay could keep interactive. (View on GitHub)
1. Current Progress
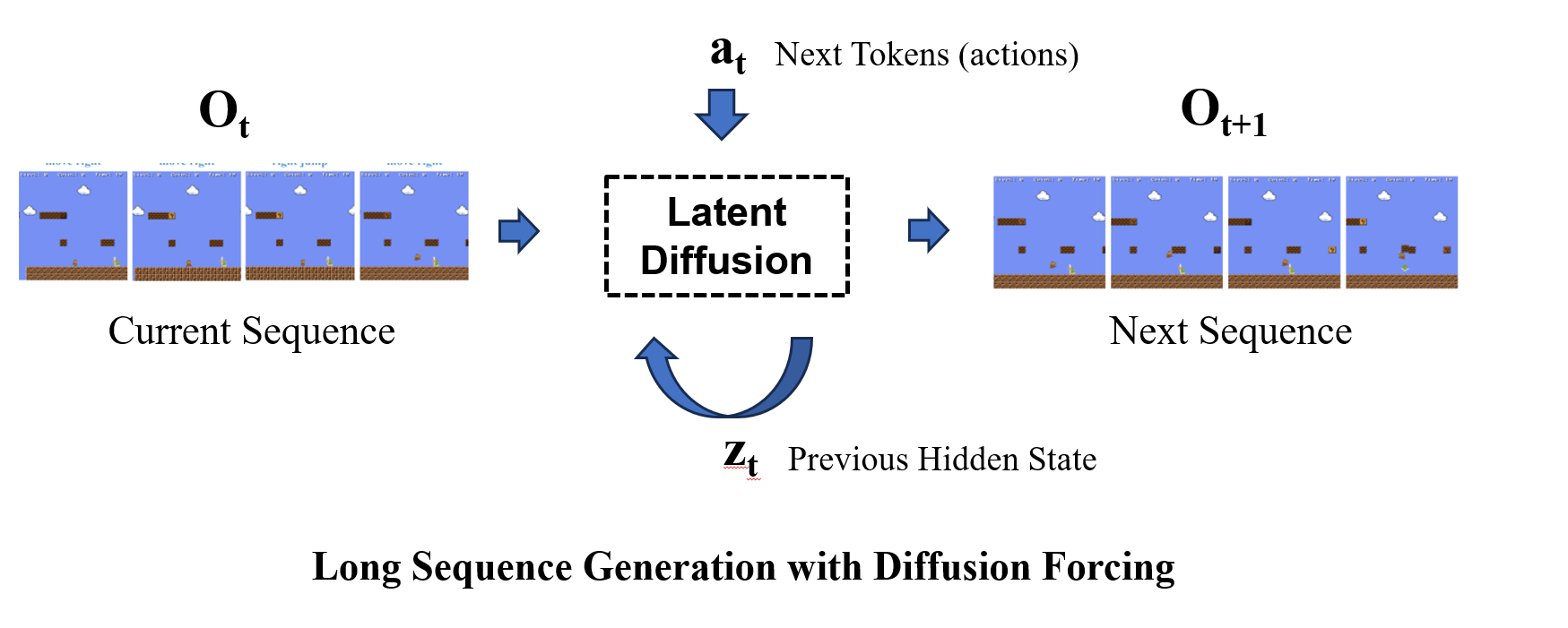
we build up a game-generative framework that supports: efficient latent representation of visual content via Variational Autoencoder, a robust temporal modeling and conditional generation pipeline using latent diffusion with memory, and a light weight DiT structure that could keep frame to frame render consistency in real time.
2. To DO List
🚧 In Progress
- PPO Policy AI Agent Training: Implementing Proximal Policy Optimization algorithms for intelligent agent behavior learning and large-scale data collection
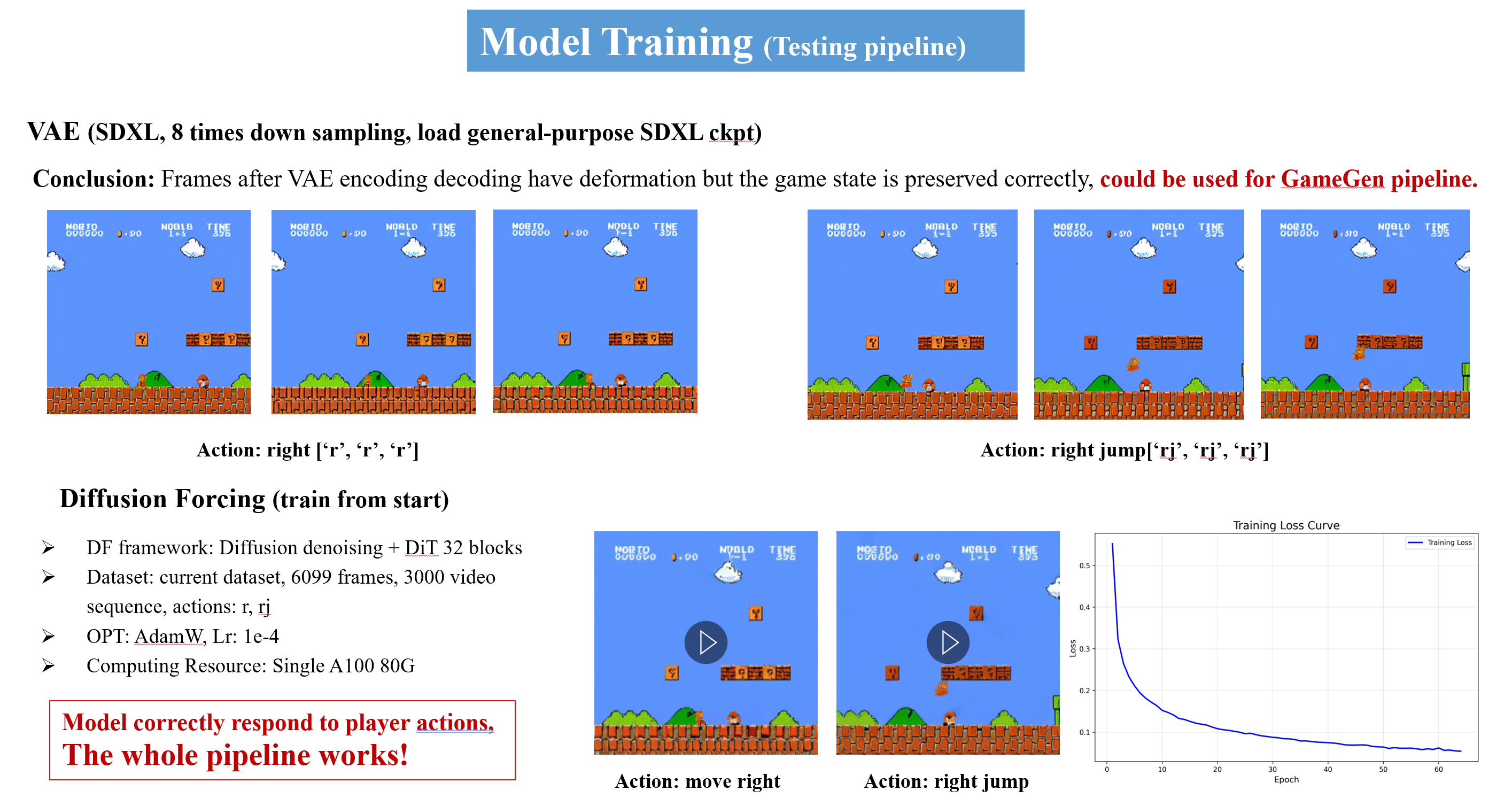
- VAE Model Enhancement: Optimizing Variational Autoencoder architecture to improve image encoding and decoding quality
- Large-scale Diffusion Model Training: Loading extensive datasets to train robust diffusion models for high-quality game content generation
🔄 Development Pipeline
- Data Collection: Automated gameplay data gathering through AI agent interactions
- Model Optimization: Continuous improvement of VAE and Diffusion DiT architectures
- Performance Evaluation: Comprehensive testing and validation of generated content quality